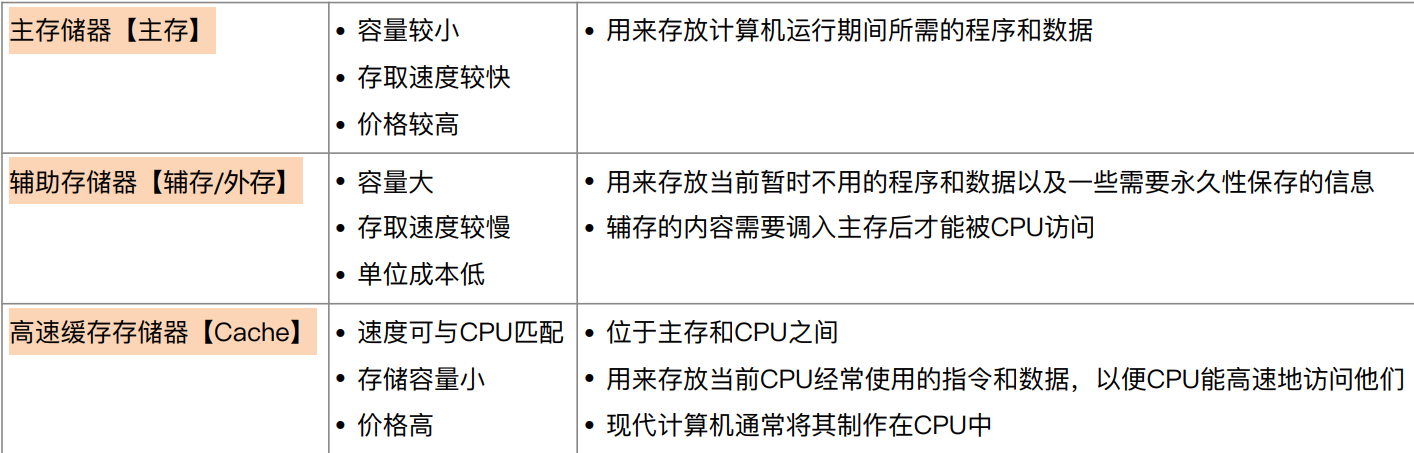
存储器概述
存储器分类
-
按计算机中作用(层次)
-
按存储介质
磁表⾯存储器:磁盘,磁盘
磁芯存储器
半导体存储器:MOS型存储器,双极型存储器
光存储器:光盘
-
按存取方式
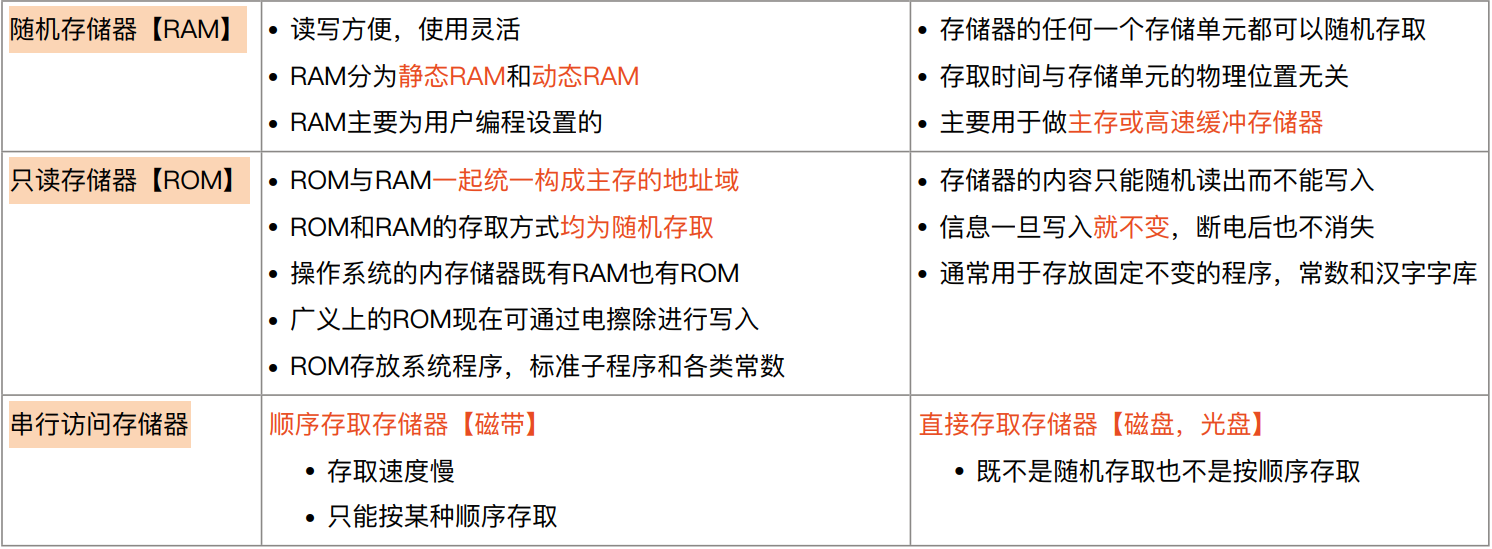
-
按信息可保持性
- 易失性存储器
- 非易失性存储器
存储器性能指标
-
存储容量
- 存储容量=存储字数 × 字长(1M × 8bit)
- 存储字数表示存储器的地址空间⼤⼩ MAR
- 字⻓表示⼀次存取操作的数据量MDR
-
单位成本
每位价格=总成本/总容量
-
存取速度
数据传输率(每秒信息传输位数) = 数据的宽度/存储周期
- 存取时间Ta:启动一次存储器到完成的时间,分为读出和写入时间
- 存取周期Tm:进行一次完整读写操作所需全部时间
- 主存带宽Bm = 数据传输速率 = 每秒从主存进出信息最大数量 = 字/秒
存取时间不等于存储周期

多级层次存储系统
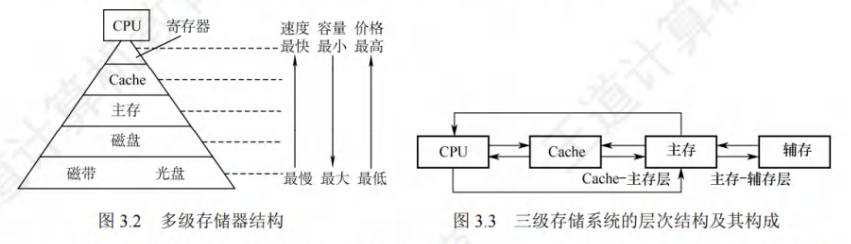
主要体现在:Cache—主存层和主存—辅存
上⼀层的存储器作为低⼀层存储器的⾼速缓存,上⼀层的内容是下⼀层内容的⼀部分
CPU读取顺序:cache——主存——磁盘
- 主存、Cache,硬件⾃动完成,解决CPU与主存速度不匹配,对所有程序员透明
- 主存、辅存,硬件和os共同完成【换⼊换出技术】,对应⽤程序员透明
主存储器
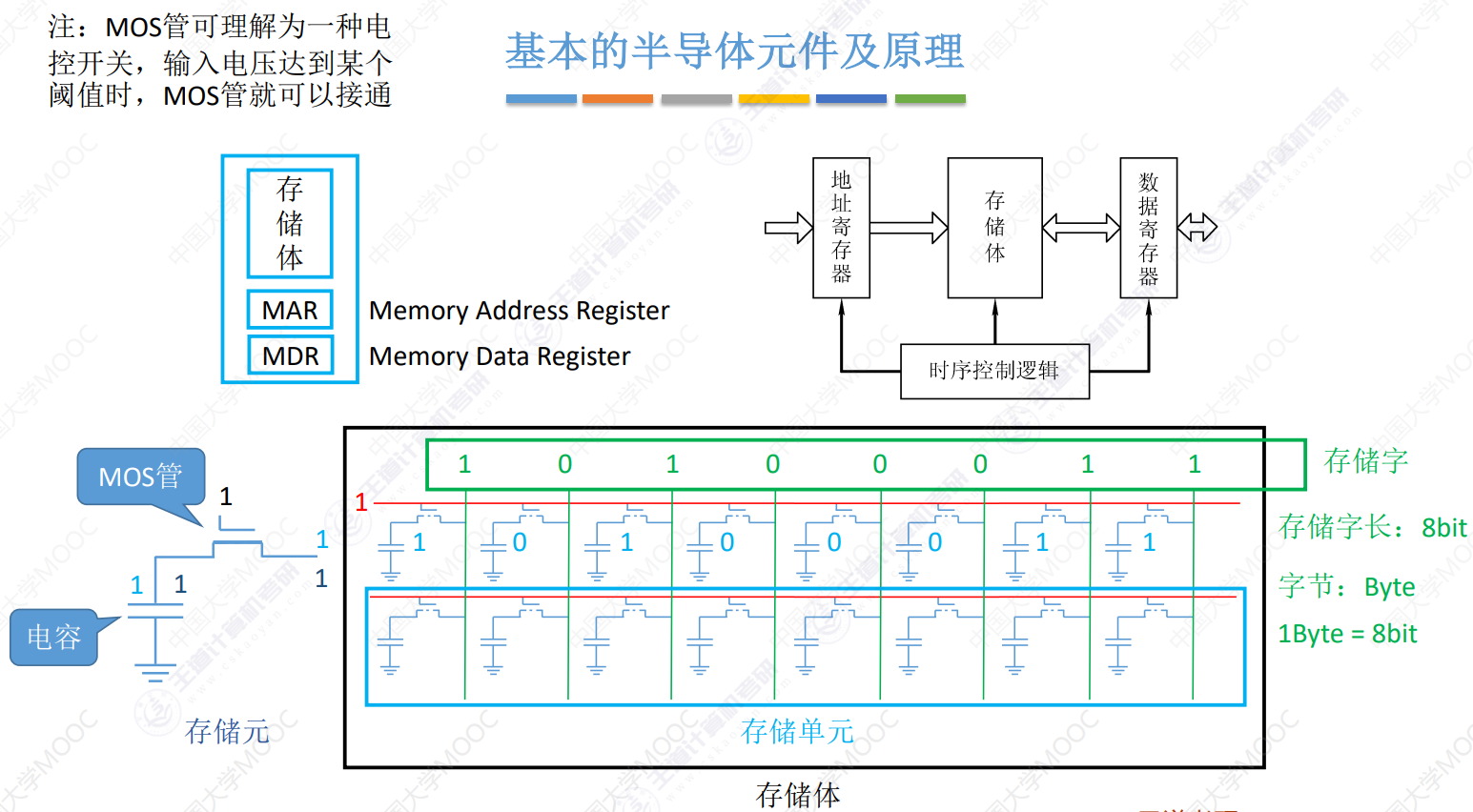
存储器基本组成
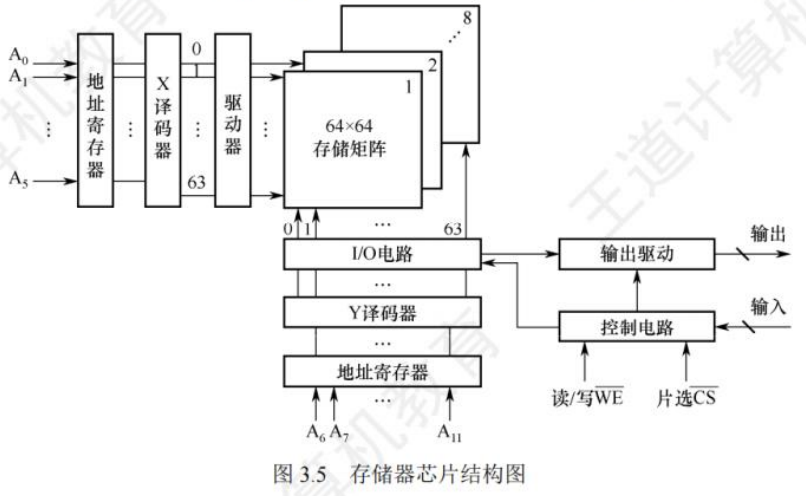
存储器芯片内部结构
-
存储体
存储单元的集合,通过x,y选择线选择存储单元
-
地址译码器
将地址转换为译码器输出线中的高电平,驱动对应字选线
-
I/O控制电路
控制选中单元读入或写出
-
片选控制信号
选择指定存储芯片可读写
-
读/写控制信号
控制被选中单元进行读或写
存储体数据读取原理
-
mos管控制数据读取
- mos管通电时,电容内有电荷则有电流输出,表示1,反之则为0
- 红色线即mos管通电线路,用于控制是否读取数据
- 绿色线用于输出电容内数据
-
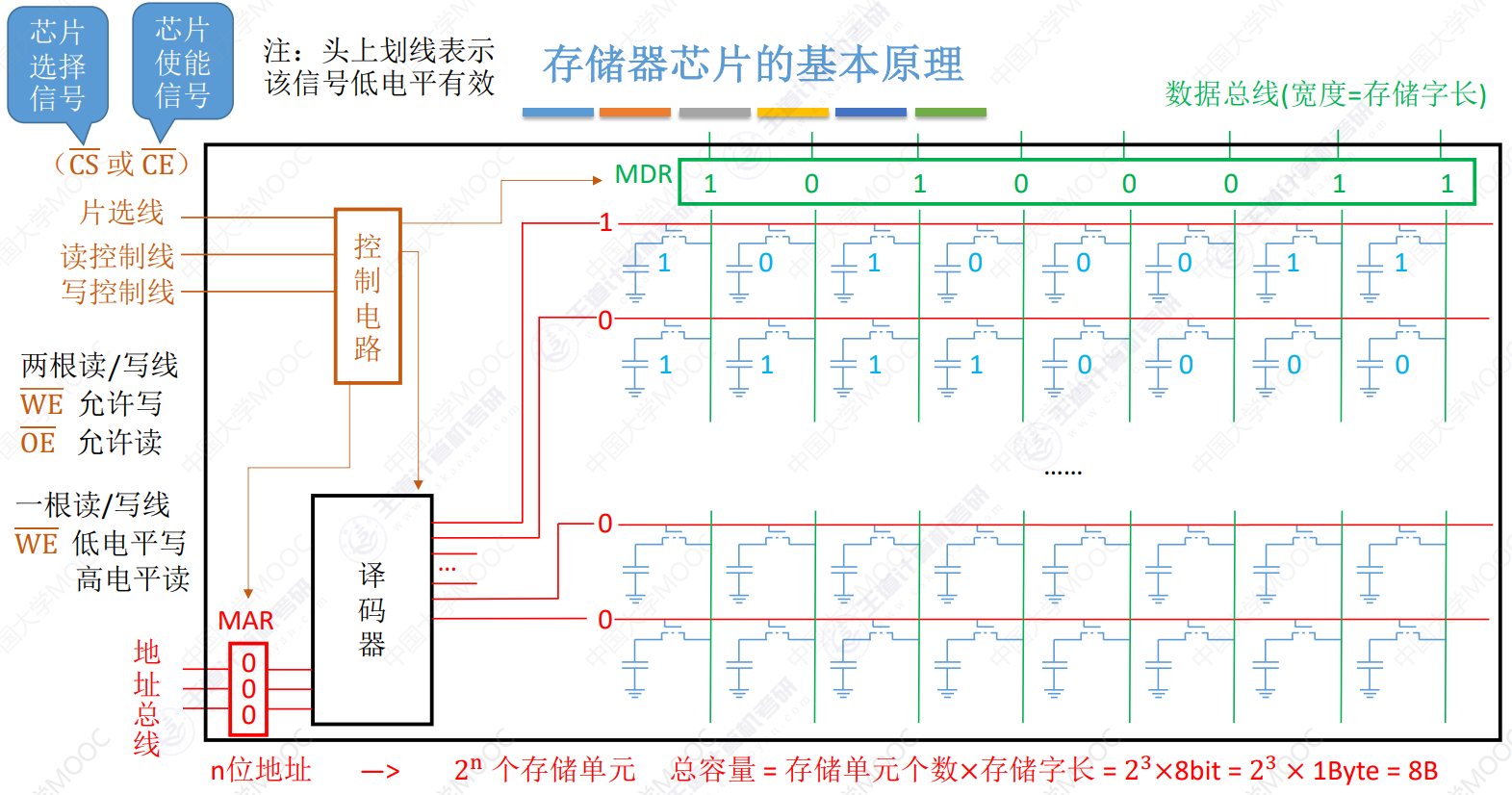
由地址确定需要读取的存储字
- n位地址,对应2n个存储单元
- 存储器地址寄存器(MAR)给出需要访问的地址
- 译码器将地址信息转换为对应字选线(红色线)的高低电平,高电平时读出存储单元数据
- 存储器数据寄存器(MDR)暂存由存储单元读取出或需要输入的信息
- 控制电路控制MAR和MDR电平稳定后输入输出
- 绿色线即数据总线——宽度与存储字长相同
- 片选线可能为1、2根,控制指定一条内存上的一块存储芯片
存储容量常见描述如:1K × 8位,即表示有1000个存储单元,每个存储单元内有8个二进制位,即存储字长为8需要8根数据总线,1000=210个存储单元需要10位地址,即需要10根地址线
随机存储器(RAM)
- 静态随机存储器(SRAM,Static Random Access Memory)
- 动态随机存储器(DRAM,Dynamic Random Access Memory)
| SRAM | DRAM | |
|---|---|---|
| 主要用途 | 处理器cache | 主存储器 |
| 存储信息 | 双稳态触发器 | 栅极电容 |
| 破坏性读出 | 否 | 是 |
| 刷新 | 不要 | 需要 |
| 行列地址 | 一次送 | 两次送 |
| 速度 | 高 | 低 |
| 集成度 | 低 | 高 |
| 存储成本 | 高 | 低 |
RAM只要断电都会丢失数据
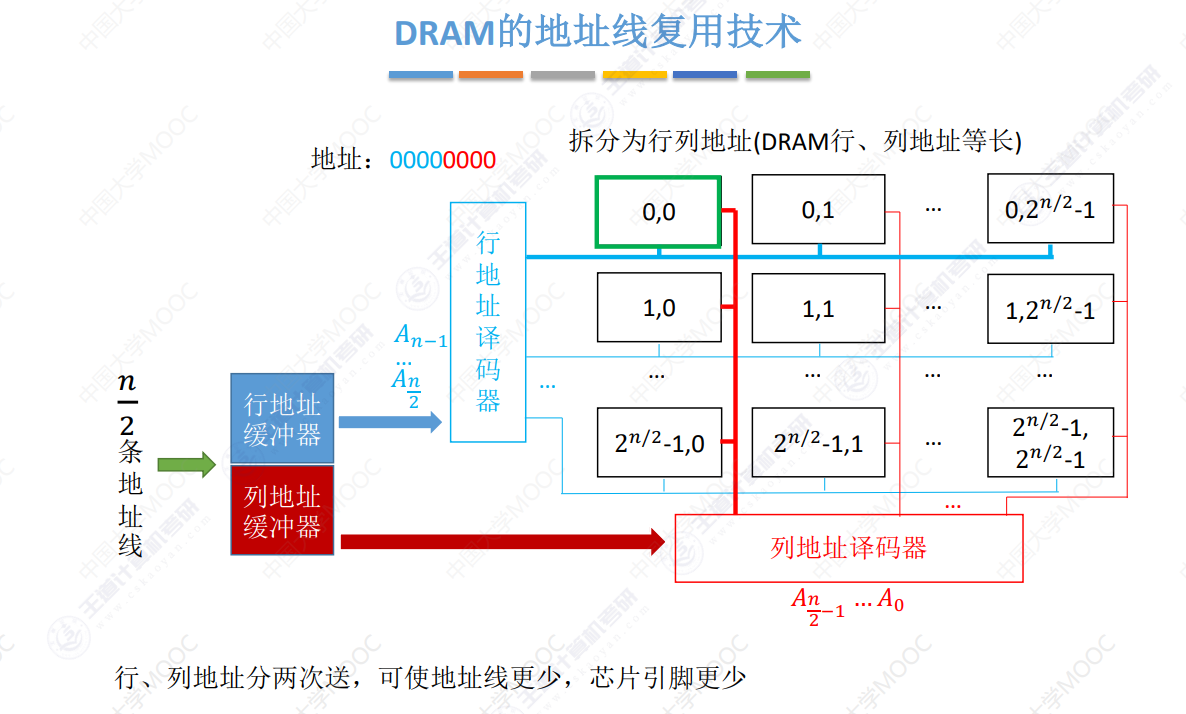
地址线复用技术
对于n位地址,将前n/2位作为行地址,后n/2位作为列地址
使用n/2条地址线分两次传送,经过行列地址译码器译码后,激活对应行列选通线
行列选通线同时接通即读取对应存储单元
DRAM的刷新
DRAM电容电荷通常维持2ms,需要读取后重写,对同一行的两次刷新间隔时间即刷新周期,刷新周期通常为2ms
刷新为一次读一次写,故占用一个存取周期
假设有存取周期0.5us,2ms共4000个周期,DRAM为128×128
-
集中刷新
利用一个刷新周期内固定的一段时间,对所有行逐一刷新
期间停止所有读写操作——死时间,访存死区

-
分散刷新
每次读写完都进行一次刷新,则存取周期×2变为1us
没有死区

-
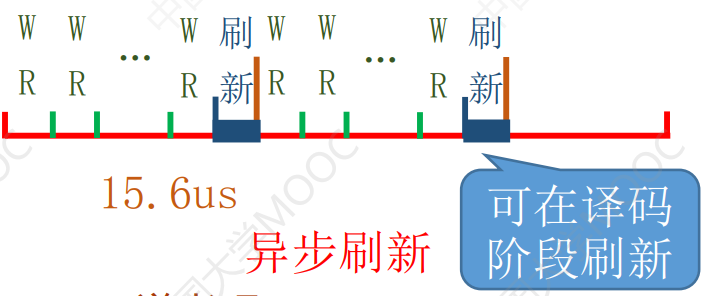
异步刷新
一个刷新周期内,一行只需要刷新一次
刷新周期/行数=2ms/128=15.6us
即每15.6us有一次死时间,可以利用CPU不需要读写的时候进行刷新
同步DRAM芯片(SDRAM)
DRAM采用异步方式与CPU交换数据,在读写完成之前CPU不能进行其他工作
SDRAM使用同步方式,由系统时钟控制操作,现代主存常用
只读存储器(ROM)
ROM特点
- 结构简单,位密度比RAM高
- 非易失性,可靠性高
ROM类型
-
掩模式只读存储器(MROM,Mask Read-Only Memory)
内容在⽣产过程中写⼊
可靠性⾼,集成度⾼,价格便宜但灵活性差
-
⼀次可编程只读存储器(PROM,Programmable Read-Only Memory)
⽤于使用专用编程器写入信息后,就不可更改
-
可擦除可编程只读存储器(EPROM,Erasable Programmable Read-Only Memory)
允许⽤户实现多次性编程
可多次改写,但次数有限,写⼊时间过⻓
-
EEPROM
可用“电擦除”的方式,擦除特定的字
-
-
闪速存储器(Flash Memory)
在EEPROM 基础上发展而来,断电后也能保存信息,且可多次快速擦除重写
闪存写入时需要擦除,因此读速度>写速度
-
固态硬盘(SSD,Solid State Drives)
SSD即闪存,是⼀种⾮易失性存储器,采⽤随机访问⽅式
可⻓期保存信息,快速擦除和重写
读写速度快、低功耗,但价格较⾼
BIOS芯片
BIOS芯片也是ROM,其中包含自举装入程序
计算机启动时,调用BIOS自举装入程序引导装入操作系统
BIOS芯片也是主存的一部分,计算机对主存的编址由BIOS开始
多模块存储器
空间并⾏技术,利⽤多个结构完全相同的存储模块的并⾏⼯作来提⾼存储器的吞吐率
单体多字存储器
存储器中只有⼀个存储体,每个存储单元存储m个字,总线宽也为m个字,地址必须顺序排列并处于同⼀存储单元
指令和数据若无法连续存放,即无法一并取出,则效率降低
多体并行存储器
多体模块组成,每块都有相同容量和读取速度,各模块都有独⽴的读写控制电路、MAR和MDR
-
高位交叉编址
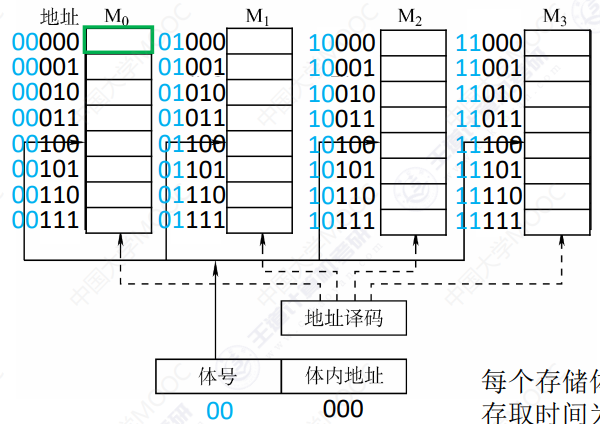
读取连续数据时,无法提高读取速度
连续地址在同一存储体内连续排列
-
低位交叉编址
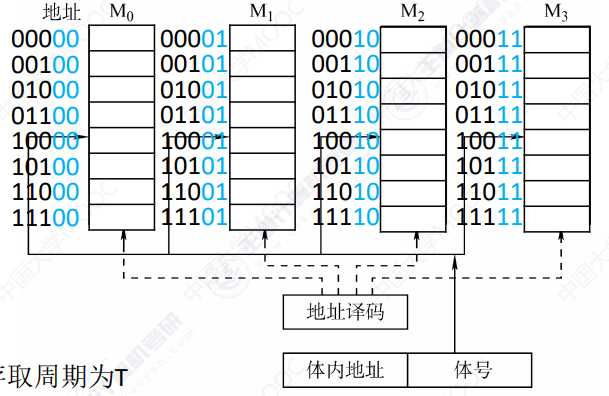

对连续字的成块传送可实现多模块并⾏存取,提⾼了存储器的带宽
-
连续地址在m个模块内交替循环排列,模块号=地址%m
-
模块字长等于数据总线宽度,模块存取字周期为T,总线传输周期r
-
存储器模块数量:m>T/r
-
取m个字的时间为:T+(m-1)r

-
访问冲突的规则:访存地址在相邻的m次访问中出现在同⼀个存储模块中
-
主存储器与CPU的连接
连接原理
- 主存储器通过数据总线、地址总线、控制总线与CPU连接
- 数据总线位数、工作频率乘积,与数据传输速率成正比
- 地址总线位数——可寻址最大内存空间
- 控制总线(读/写)——指出总线周期类型,输入输出操作完成时刻
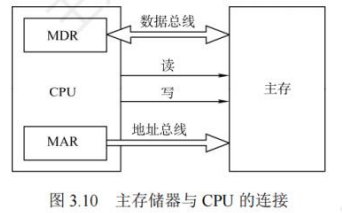
实际上在现代存储系统中,MAR和MDR都是CPU的一部分,主存内只存在简单寄存器暂存输入输出数据
-
读写控制线
WE 或 WR
可能分开为 WE 和 OE 两根读写线
-
片选线
CS 或 CE
主存容量扩展
位扩展
增加存储字长,使得存储芯片数据位数等于CPU数据总线宽度
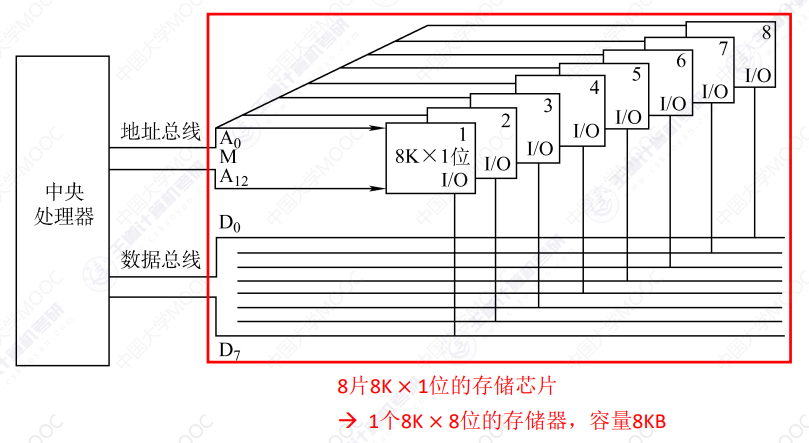
8K*8位 存储器 = 8⽚ 8K*1位 RAM
字扩展
存储字位数满足CPU要求时,增加存储字数量
数据总线宽度等于芯片数据线位数,地址总线位数多于芯片地址线位数
此时多块存储芯片并联于数据总线,为了访问指定存储芯片,需要片选信号:
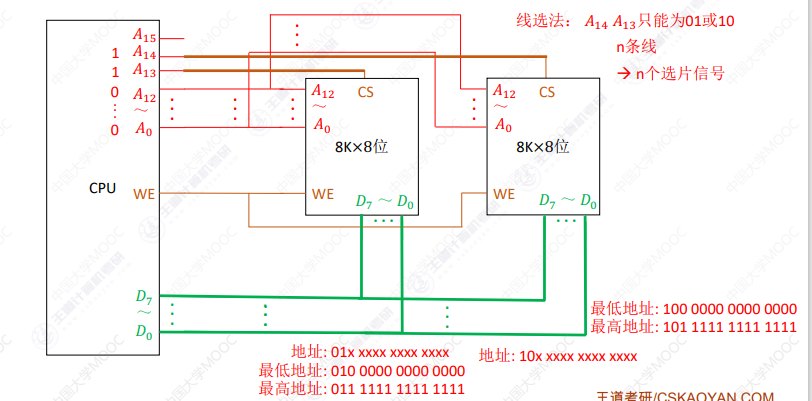
线选法
谁⼯作,数据线就接送谁的数据,即将CS设置为1
2位二进制时:只能利用01、10,浪费11和00地址空间,导致地址空间不连续
译码片
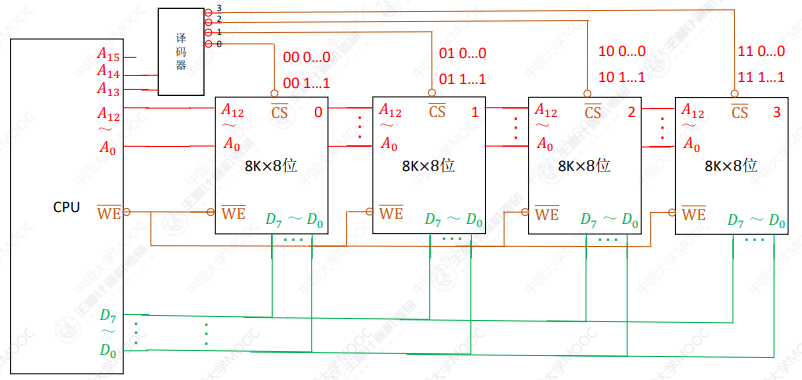
高位地址线通过地址译码器阐释片选信号
4片芯片只需要2条高位地址线译码,即参考地址总线译码器,n条线,对应2n片芯片
此时地址连续,不浪费地址空间,但是译码器提高成本
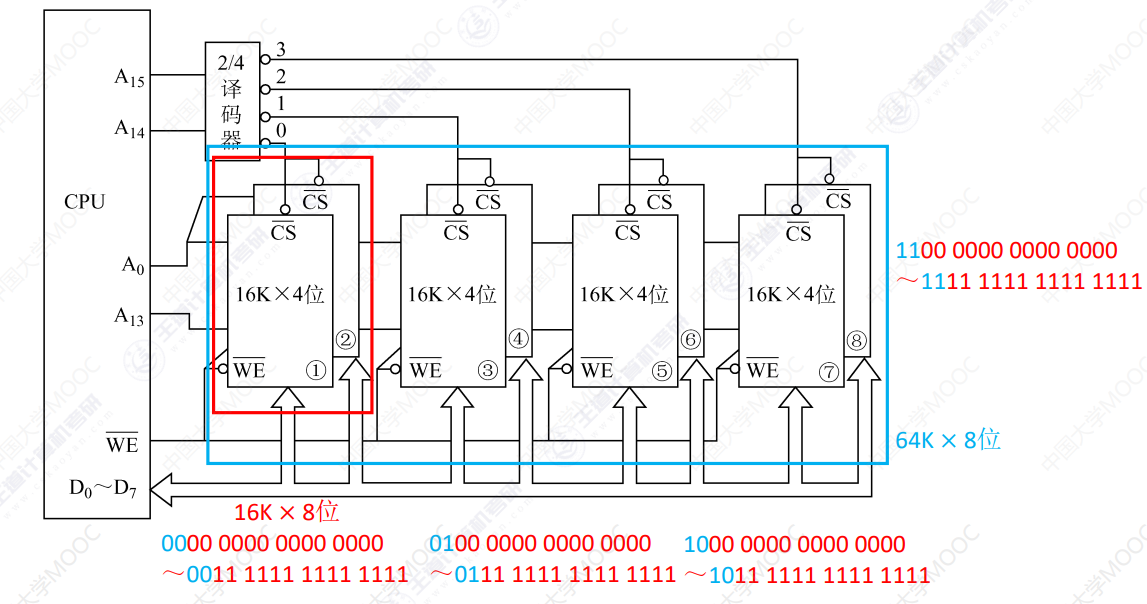
字位同时扩展
⼀块芯⽚只有4位,因此通过2⽚叠加先实现位拓展
等价于实现了⼀个8位的存储芯⽚
再通过译码⽚选的⽅式实现字拓展
在不同的地址线中选择不同的芯⽚组合进⾏⼯作
外部存储器
见操作系统——输入输出管理——磁盘和固态硬盘
高速缓冲存储器
cache工作原理
局部性原理
-
时间局部性
程序中的某条指令⼀旦执⾏,则不久之后该指令可能再次被执⾏
如果某数据被访问,则不久之后该数据可能再次被访问【例如循环】
-
空间局部性
⼀旦程序访问了某个存储单元,则不久之后其附近的存储单元也将被访问
【例如对数组的访问,如果数组按行存的,则先行再列的取方式空间局部性更好】
cache利用了局部性原理,使得CPU进行访存操作时,尽可能访问更快的cache而不是较慢的内存,提高效率
当访问cache得不到需要的数据,转而再访问主存
CPU、cache、内存读写关系
-
CPU发出读请求
访存地址命中cache,直接对cache读操作,以字为单位
访存地址未命中,cache访问主存按块读取目标
-
CPU发出写请求
cache命中时,讨论和主存的一致性问题
未命中时,按一定的写策略处理
cache性能分析
-
cache命中率
$\frac{cache总命中次数}{cache总命中次数+访问主存总次数}$
-
系统平均访问时间
$命中的概率×命中所需要花费的时间+缺失的概率×平均访存次数×一次总线读突发总线事务所需时间$
cache和主存的映射方式
全相联映射
随意放
主存与cache以块为交换单位,因此在cache中使用块号作为主存位置的标记
使用一位有效位标记cache内数据是否有效
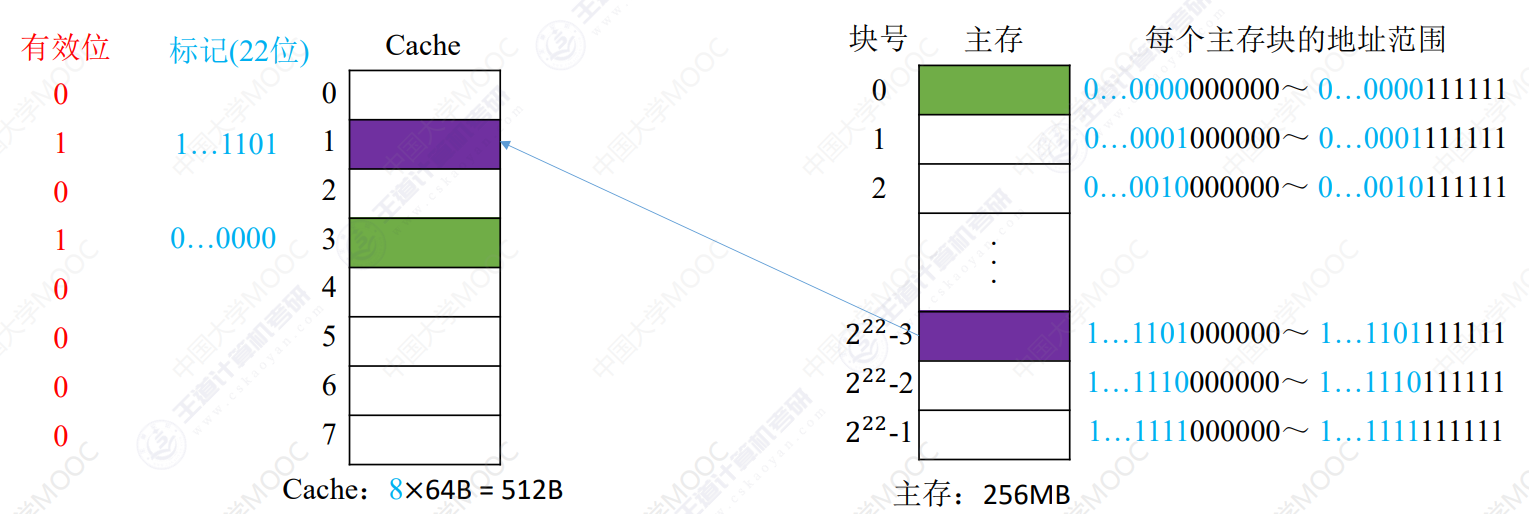
-
CPU访存
- CPU从地址分离出块号,在cache中查找对应标记
- 若标记命中且有效位为1,命中
- 未命中,则正常访问主存
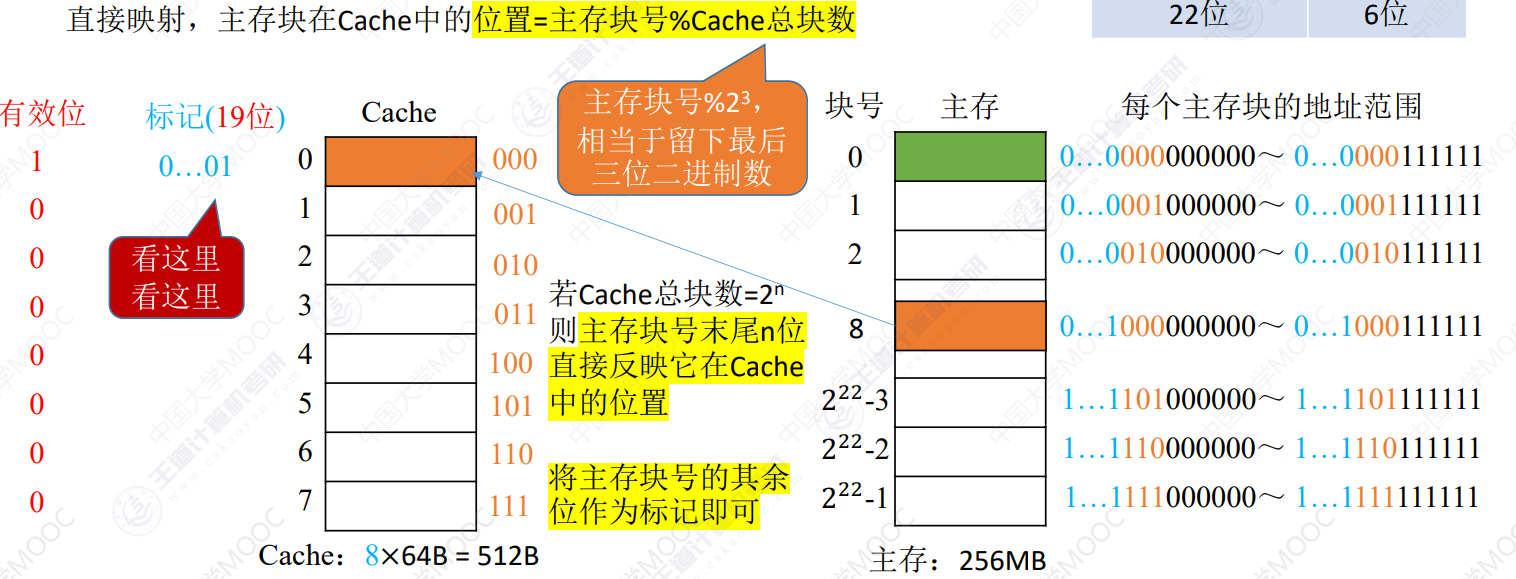
直接映射
主存中每块在cache中的位置固定 = 主存块号 % Cache总块数2**N**
若cache有23块,则主存块在cache中的保存位置为主存块号的最后3位二进制数
即取标记为块号其余位
-
CPU访存
- CPU从地址分离出块号,在块号中得到后n位确定cache位置
- 若标记匹配且有效位为1,命中
- 未命中,则正常访问主存
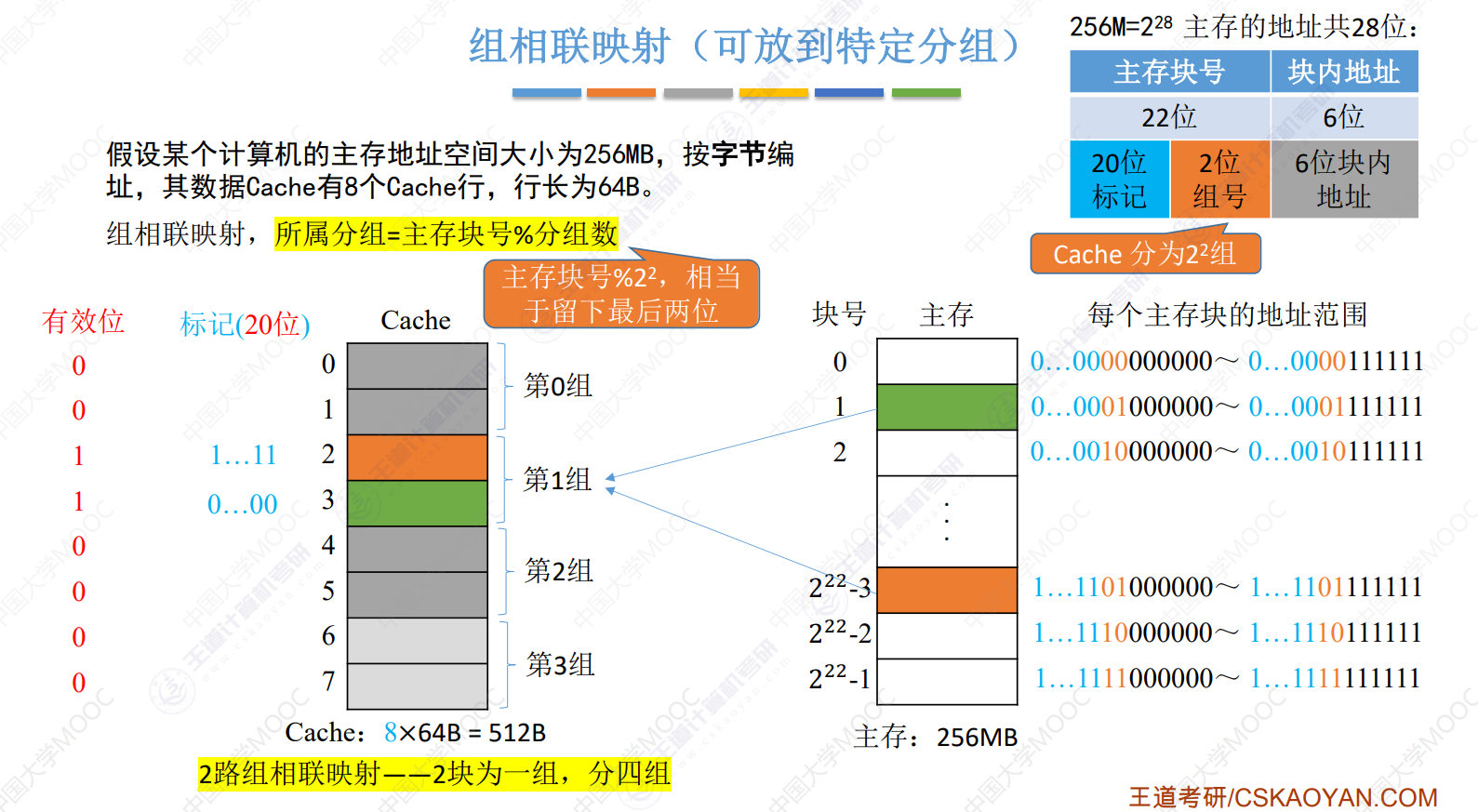
组相联映射
先按块号分组,组内使用全相联映射,随意放
n路组相联映射——n块一组
所属分组=主存块号 % 分组数
-
CPU访存
- CPU从地址分离出块号,在块号中确定cache组号
- 若组内标记匹配且有效位为1,命中
- 未命中,则正常访问主存
cache中主存块替换算法
只有全相联映射和组相联映射需要考虑替换算法
直接映射位置固定,需要则直接替换
随机算法NAND
Cache满,随机选择一块替换
实现简单,完全不考虑局部性原理,命中率低,实际效果不稳定
先进先出算法FIFO
若Cache已满,则替换最先被调入Cache的块
实现简单,不考虑局部性原理,出现抖动现象
抖动现象: 频繁换入换出,刚被换出的块很快又被调入
近期最少使用LRU
每个cache块设置一个计数器,替换时选择计数器最大的块
- 命中时,命中块计数器归零,比归零前低的计数器+1,其余不变(Cache块的总数=2n,则计数器只需n位。且Cache装满后所有计数器的值一定不重复)
- 未命中且有空闲,装入块计数器归零,非空闲块全部+1
- 未命中且无空闲,计数最大块淘汰归零,其余全部+1
LRU算法的实际运行效果优秀,Cache命中率高
若被频繁访问的主存块数量 > Cache行的数量,则有可能发生“抖动”
最近不经常使用LFU
为每个cache块设置一个计数器,记录被访问次数,替换时选择计数器最小的
新块计数器=0,每次访问计数器+1
曾经经常被访问的块不一定为来会用到(微信视频聊天),实际效果不如LRU
cache一致性问题
读操作不会导致不一致,一致性问题对写操作讨论
写命中
-
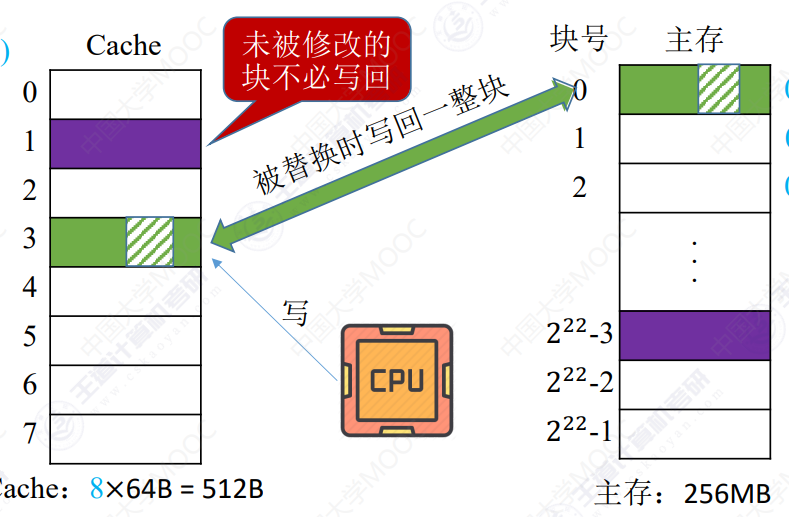
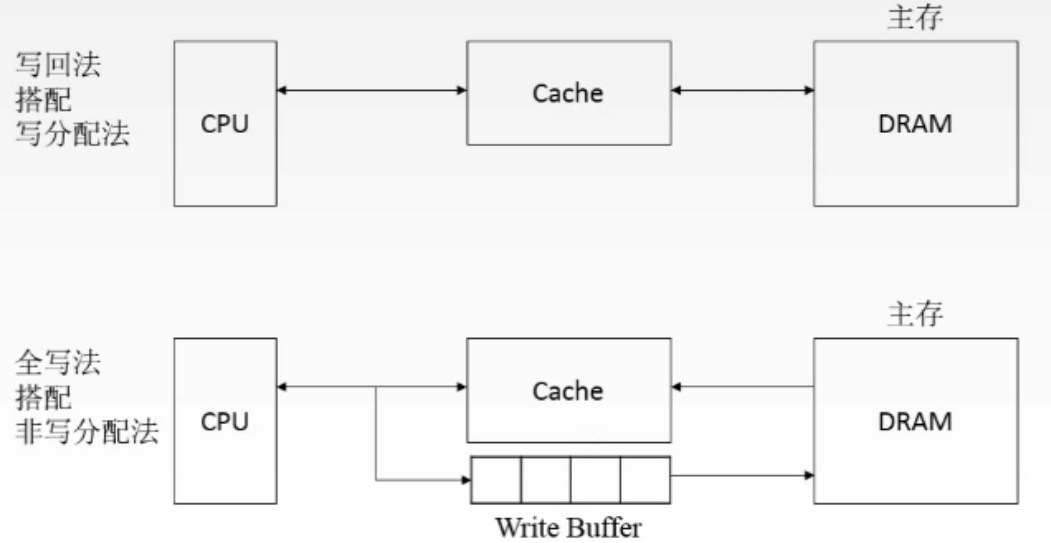
写回法
CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,块换出时才写回主存
增加脏位,标记cache块数据是否被修改
没有修改的块不写回
容易导致数据不一致
-
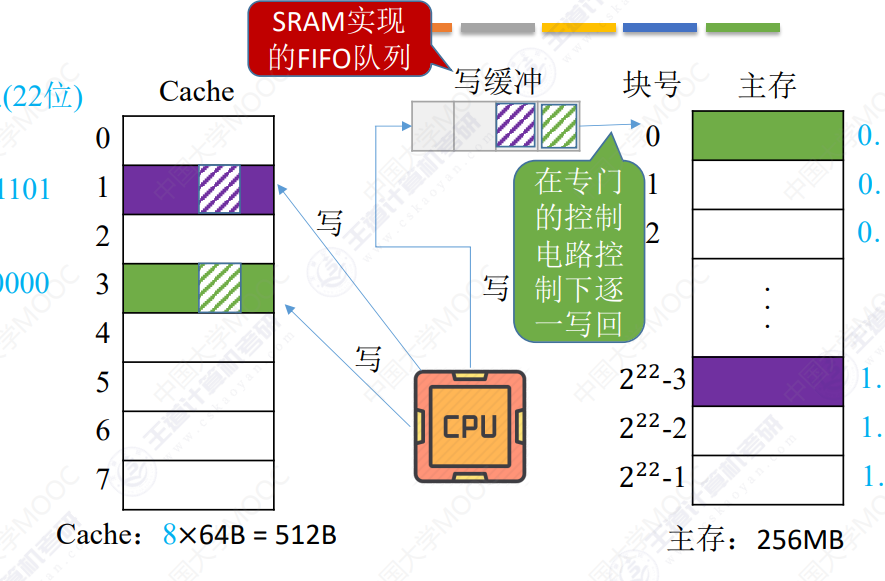
全写法
当CPU对Cache写命中时,必须把数据同时写入Cache和写缓冲(write buffer),写缓冲在专门控制电路下逐一写回主存
若写操作频繁,导致写缓冲饱和发生阻塞
写不命中
-
写分配法
当CPU对Cache写不命中时,把主存中的块调入Cache,在Cache中修改。通常搭配写回法使用
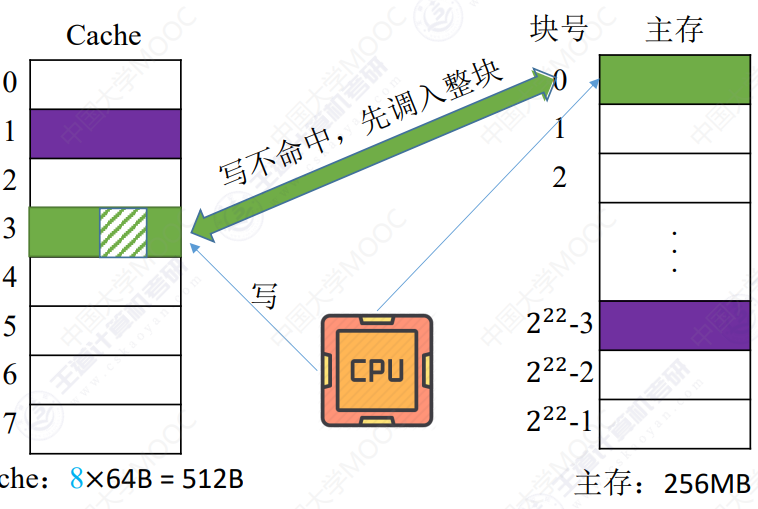
-
非写分配法
当CPU对Cache写不命中时只写入主存,不调入Cache。 搭配全写法使用

虚拟存储器
见操作系统